# Operaciones aritméticas básicas en R
2 + 3 # Suma[1] 55 - 2 # Resta[1] 34 * 5 # Multiplicación[1] 2010 / 2 # División[1] 52^3 # Potencia (2 elevado a 3)[1] 8¡Bienvenido al material introductorio de R! En este documento aprenderás los conceptos básicos de R a través de ejemplos claros y concisos.
Este es el primer material del Club de R de Agoralab. En esta sesión, aprenderemos los fundamentos de R y RStudio, herramientas esenciales para el análisis de datos y la visualización.
R es un lenguaje de programación y entorno de software libre especializado en análisis estadístico y visualización de datos. Algunas características clave:
Veamos algunas operaciones básicas en R:
# Operaciones aritméticas básicas en R
2 + 3 # Suma[1] 55 - 2 # Resta[1] 34 * 5 # Multiplicación[1] 2010 / 2 # División[1] 52^3 # Potencia (2 elevado a 3)[1] 8En R, puedes asignar valores a variables utilizando el operador <- (aunque también funciona =). La flecha <- es la forma preferida por la comunidad de R:
# Asignación de valores a variables
x <- 10 # Creamos una variable llamada 'x' y le asignamos el valor 10
y <- 5 # Creamos una variable llamada 'y' y le asignamos el valor 5
# Operaciones con variables
x + y # Suma las variables (10 + 5)[1] 15x * y # Multiplica las variables (10 * 5)[1] 50x / y # Divide las variables (10 / 5)[1] 2R maneja varios tipos de datos. Los más comunes son:
# Numéricos (números)
numero <- 42.5
class(numero) # La función class() nos dice el tipo de dato[1] "numeric"# Texto (character o cadenas de texto)
texto <- "Hola mundo"
class(texto)[1] "character"# Lógicos (TRUE/FALSE - verdadero/falso)
logico <- TRUE # Nota: TRUE y FALSE siempre en mayúsculas
class(logico)[1] "logical"Los vectores son una estructura de datos fundamental en R. Un vector es simplemente una colección ordenada de elementos del mismo tipo:
# Crear un vector numérico usando la función c() (combine)
numeros <- c(1, 2, 3, 4, 5) # c() combina valores en un vector
numeros # Mostrar el vector[1] 1 2 3 4 5# Operaciones con vectores (se aplican a cada elemento)
numeros * 2 # Multiplica cada elemento por 2[1] 2 4 6 8 10numeros + 10 # Suma 10 a cada elemento[1] 11 12 13 14 15Podemos crear vectores de cualquier tipo de datos:
Los factores se utilizan para representar variables categóricas (por ejemplo, género, grupos, categorías):
Los data frames son la estructura principal para datos tabulares en R (similar a una hoja de cálculo o tabla):
# Crear un data frame (tabla de datos)
datos <- data.frame(
nombre = c("Ana", "Juan", "Carlos", "María"), # Primera columna
edad = c(25, 30, 22, 28), # Segunda columna
altura = c(165, 180, 175, 168) # Tercera columna
)
# Ver el data frame completo
datos nombre edad altura
1 Ana 25 165
2 Juan 30 180
3 Carlos 22 175
4 María 28 168# Dimensiones (filas y columnas)
dim(datos) # Muestra (filas, columnas)[1] 4 3# Acceder a una columna usando $
datos$edad # Muestra solo la columna edad[1] 25 30 22 28# Filtrar filas que cumplan una condición
datos[datos$edad > 25, ] # Solo las filas donde la edad sea mayor a 25 nombre edad altura
2 Juan 30 180
4 María 28 168R tiene muchos paquetes que extienden su funcionalidad. Un paquete es un conjunto de funciones adicionales:
# Instalar un paquete (solo se hace una vez)
# Para ejecutar esto, quita el símbolo # del principio
# install.packages("dplyr")
# Cargar un paquete (se hace cada vez que iniciamos R)
library(stats) # Este viene preinstalado con RR tiene excelentes capacidades de visualización. Veamos algunos ejemplos básicos:
# Datos de ejemplo
set.seed(123) # Para que los resultados sean reproducibles
x <- rnorm(100) # 100 números aleatorios con distribución normal
y <- x + rnorm(100, sd = 0.5) # Valores relacionados con x + algo de ruido
# Gráfico de dispersión (scatter plot)
plot(x, y, main = "Gráfico de dispersión",
xlab = "Eje X", ylab = "Eje Y",
col = "blue", pch = 19) # pch es el tipo de punto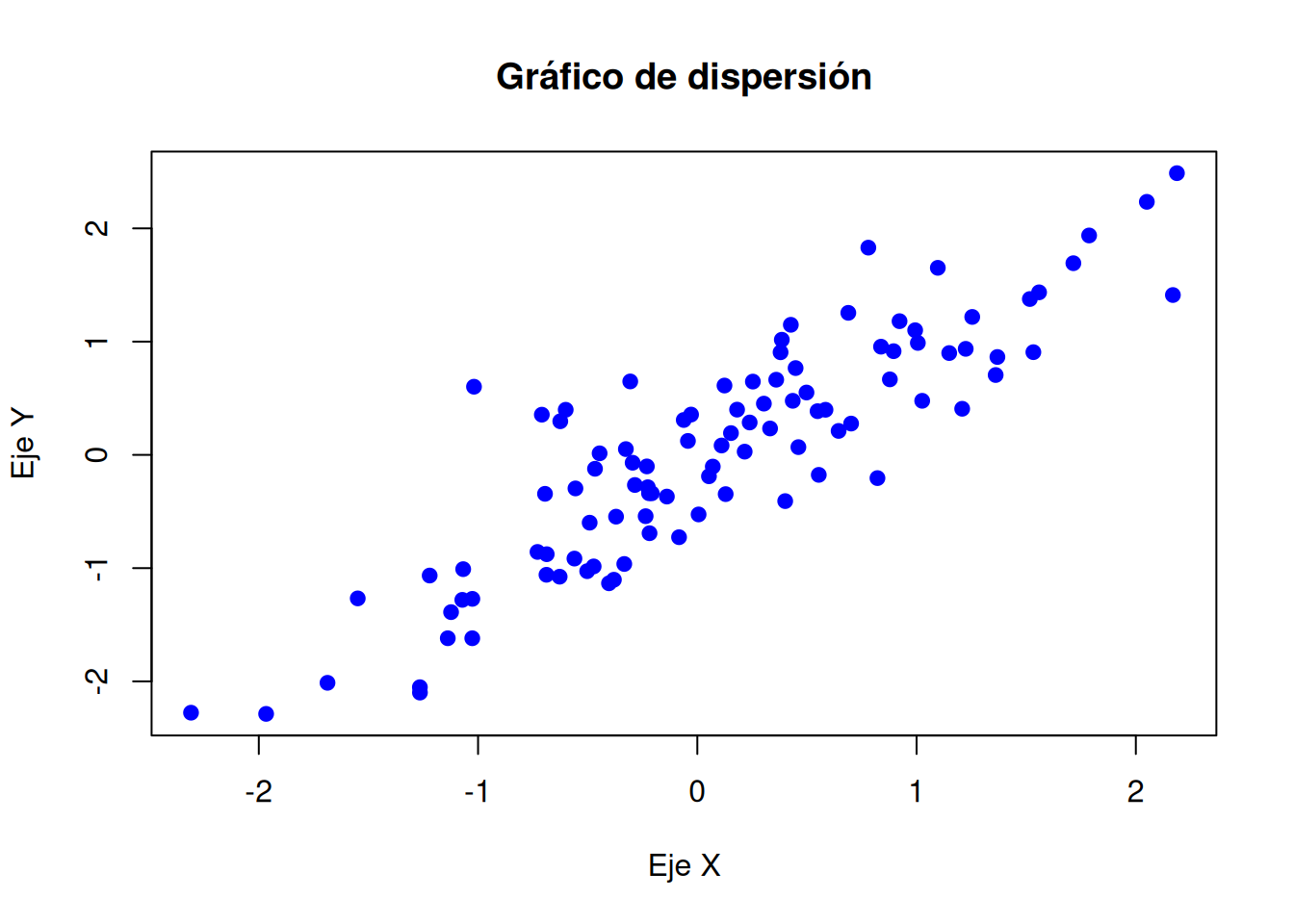
# Histograma (distribución de frecuencias)
hist(x, main = "Histograma", col = "lightblue",
border = "white", breaks = 20) # breaks es el número de barras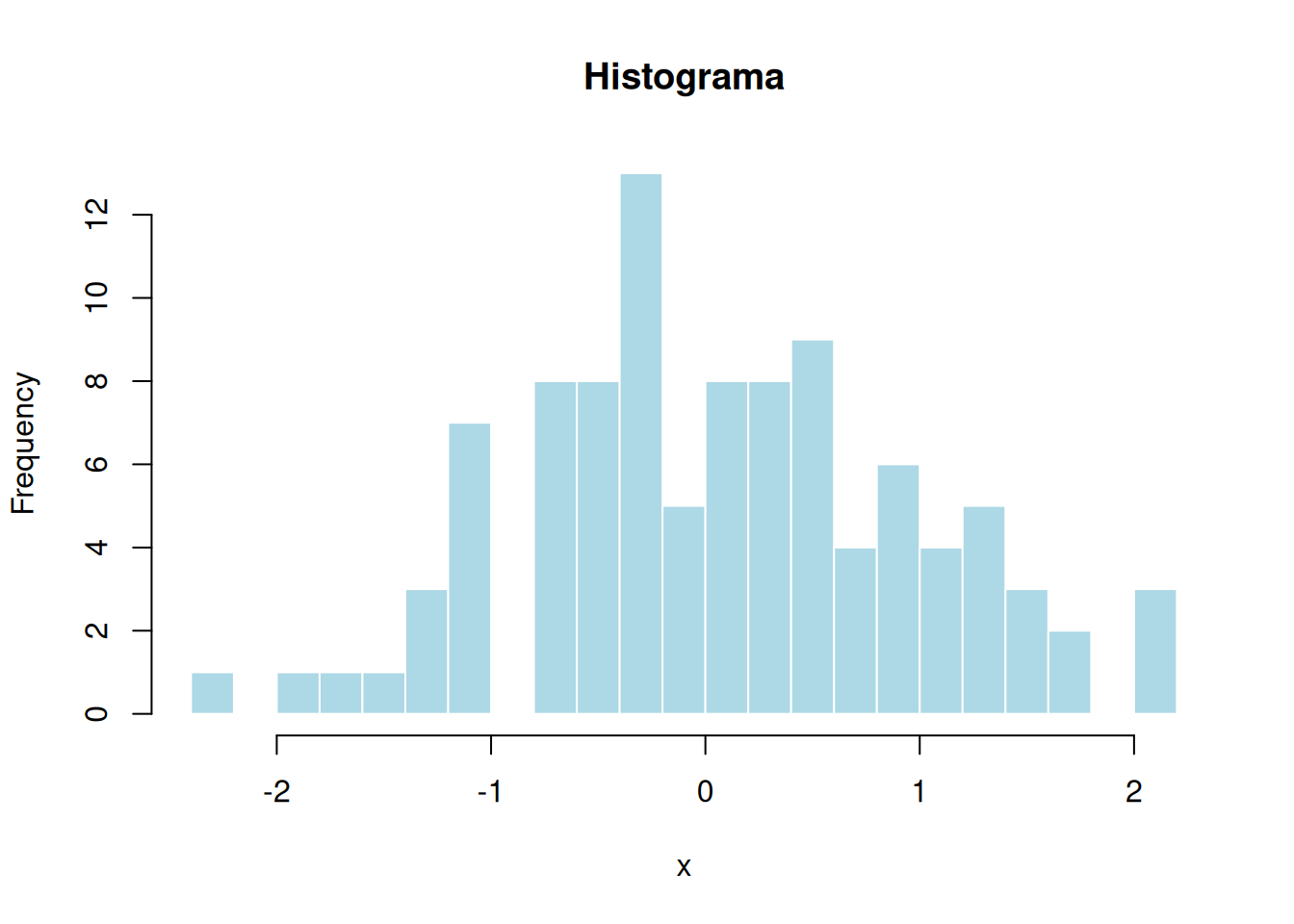
# Gráfico de barras
barplot(table(round(x)), main = "Gráfico de barras",
col = "salmon") # Cuenta los valores redondeados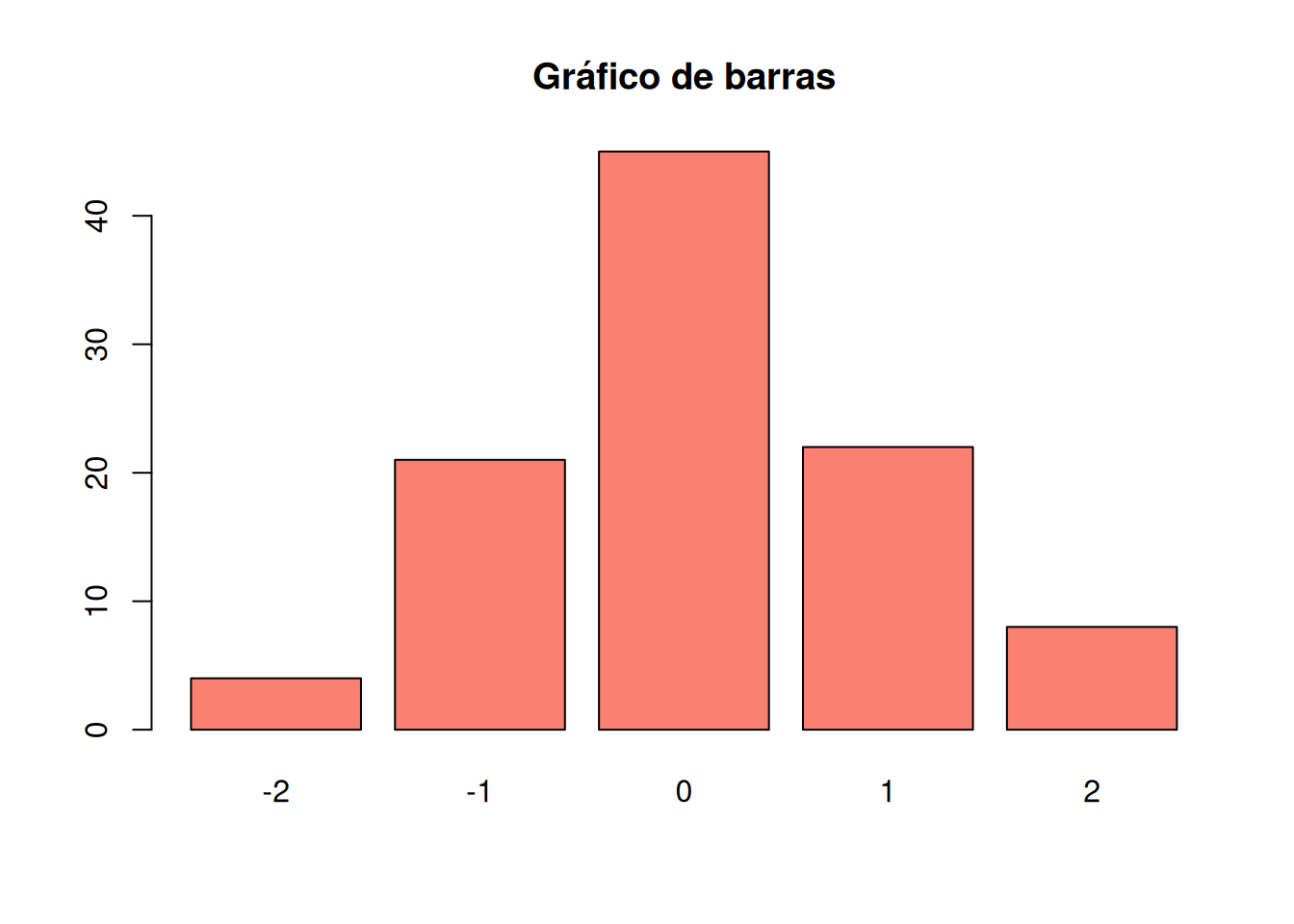
R tiene un sistema de ayuda integrado que es muy útil para aprender:
# Obtener ayuda sobre una función
?mean # Ayuda sobre la función mean (promedio)
help(sd) # Ayuda sobre la función sd (desviación estándar)
# Buscar funciones por tema
??correlation # Busca funciones relacionadas con correlaciónEn la próxima sesión, exploraremos la manipulación de datos utilizando el paquete dplyr, parte del universo tidyverse.
¿Preguntas o sugerencias? Contacta al equipo de Agoralab en agoralab@saedcnt.com.